导入mode,import与from…import的不同之处在于,简单说: 如果你想要直接输入argv变量到你的程序中而每次使用它时又不想打sys, 则可使用:from sys import argv 一般说来,应该避免使用fr…
Python 字符串前面加'r'
在Python的string前面加上‘r’, 是为了告诉编译器这个string是个raw string,不要转意backslash ‘\’ 。 例如,\n 在raw string中,是两个字符,\和n, 而不会转意为…
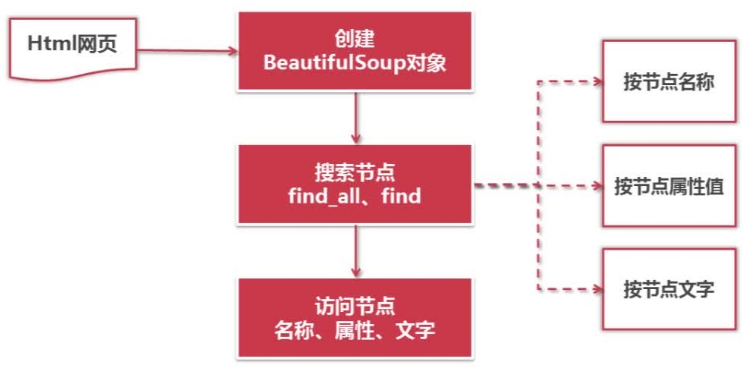
python 几种网页解析器
正则表达式——字符串形式的模糊匹配 html.parser——结构化解析 Beautiful Soup——结构化解析 lxml——结构化解析 python的网页解析器:正则表达式(文档复杂,比较复杂)、HTML.parser、Beautif…
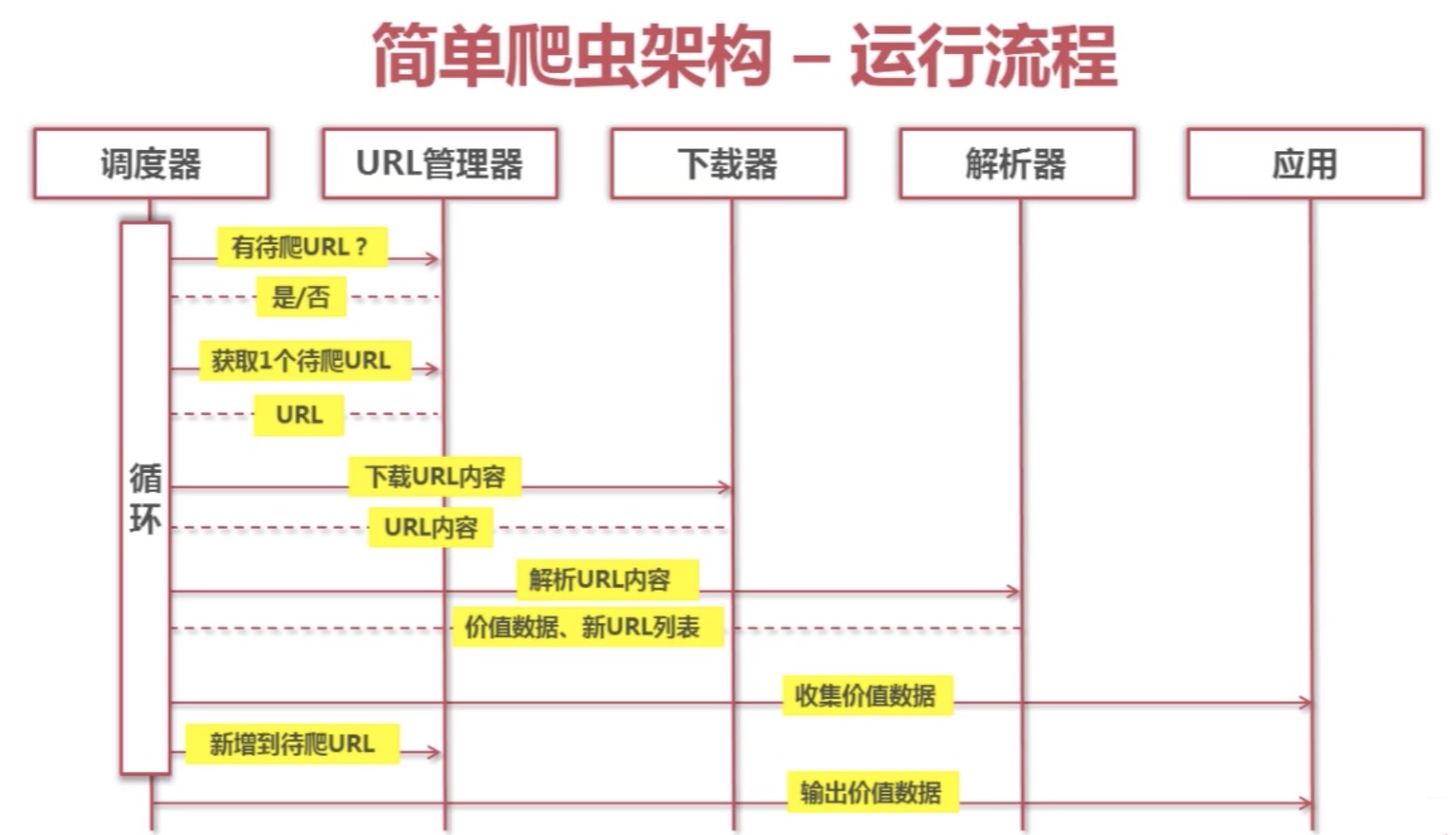
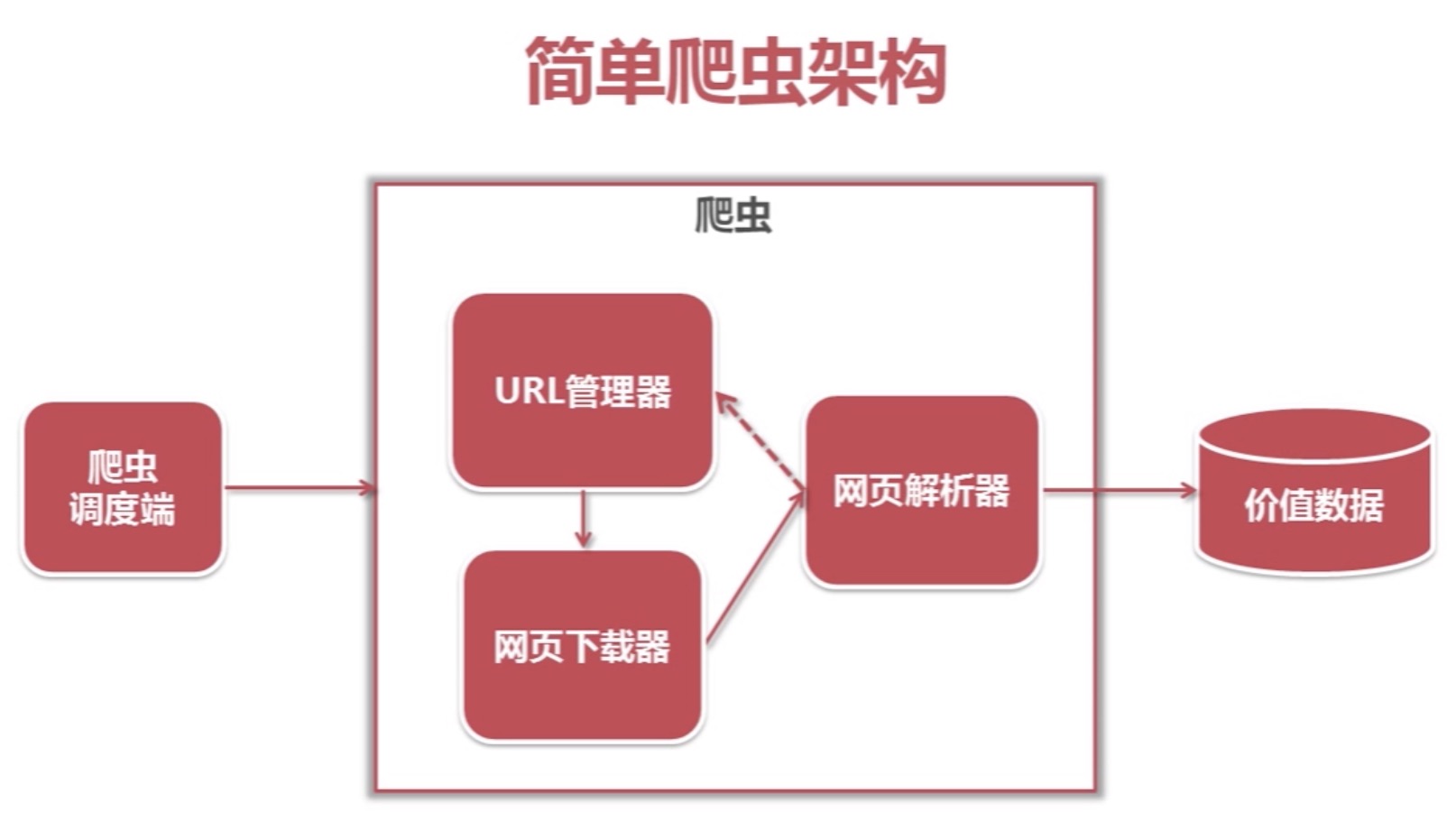
简单爬虫架构
爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器” 网页解析…
mac install python scrapy
xcode-select --install ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" brew se…
HTTPError
服务器上每一个HTTP 应答对象response包含一个数字”状态码”。 有时状态码指出服务器无法完成请求。默认的处理器会为你处理一部分这种应答。 例如:假如response是一个”重定向”,…
进程和线程关系及区别
1.定义 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位. 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只…
NoSQL是什么
NoSQL 全称为 Not Only SQL,是一种相对较新的数据库设计方式。传统的关系模型使用的是固定模式,并将数据分割到各个表中。然而, 对于大数据集的情况,数据量太大使其难以存放在单一服务器中,此时就需要扩展到多台服务器。不过,关系模…