今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(问题标题和网址),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询。 安装 在进行今天的任务之前我们需要安装二个框架,分别是Scrapy (1.1.…
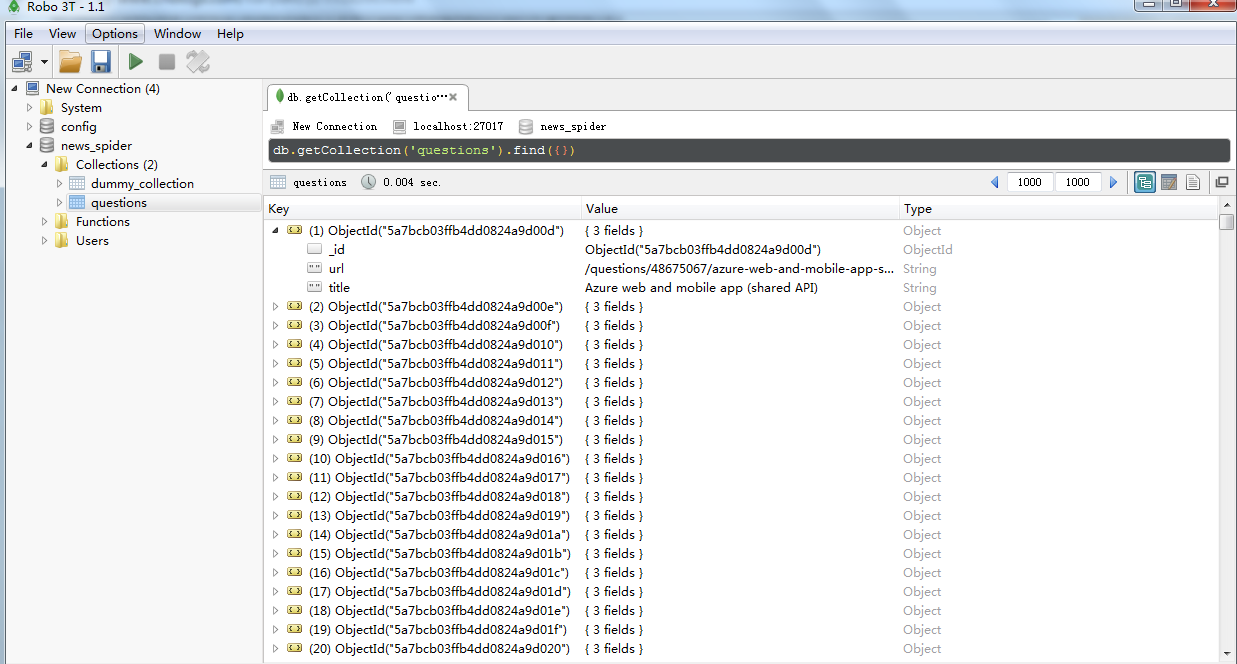
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(问题标题和网址),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询。 安装 在进行今天的任务之前我们需要安装二个框架,分别是Scrapy (1.1.…
在Python的string前面加上‘r’, 是为了告诉编译器这个string是个raw string,不要转意backslash ‘\’ 。 例如,\n 在raw string中,是两个字符,\和n, 而不会转意为…
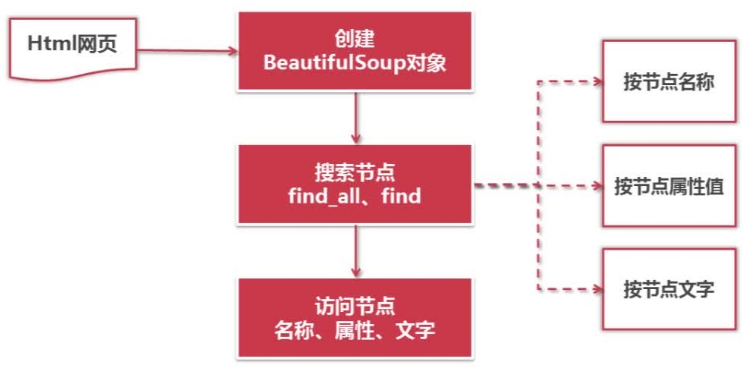
正则表达式——字符串形式的模糊匹配 html.parser——结构化解析 Beautiful Soup——结构化解析 lxml——结构化解析 python的网页解析器:正则表达式(文档复杂,比较复杂)、HTML.parser、Beautif…
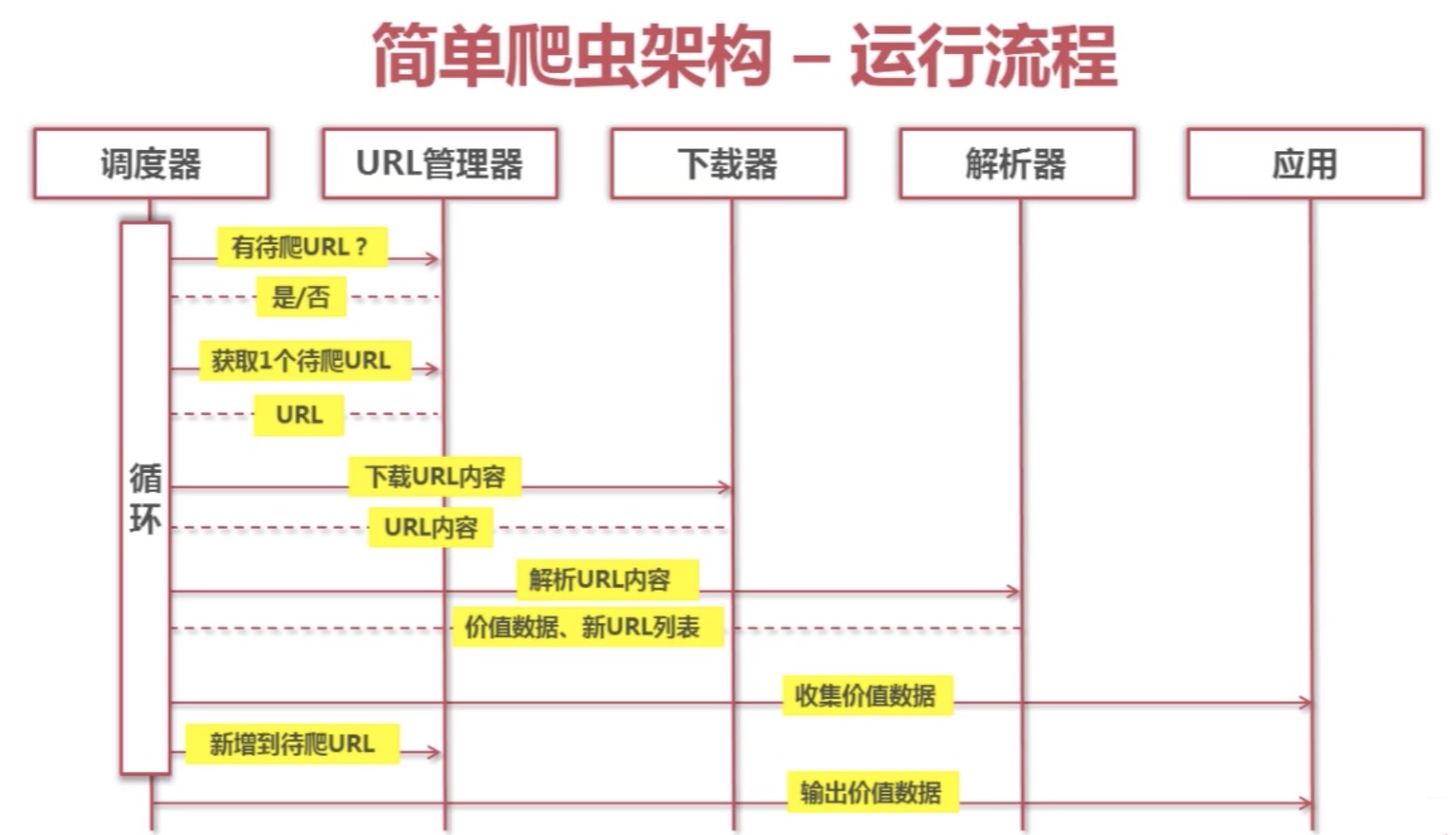
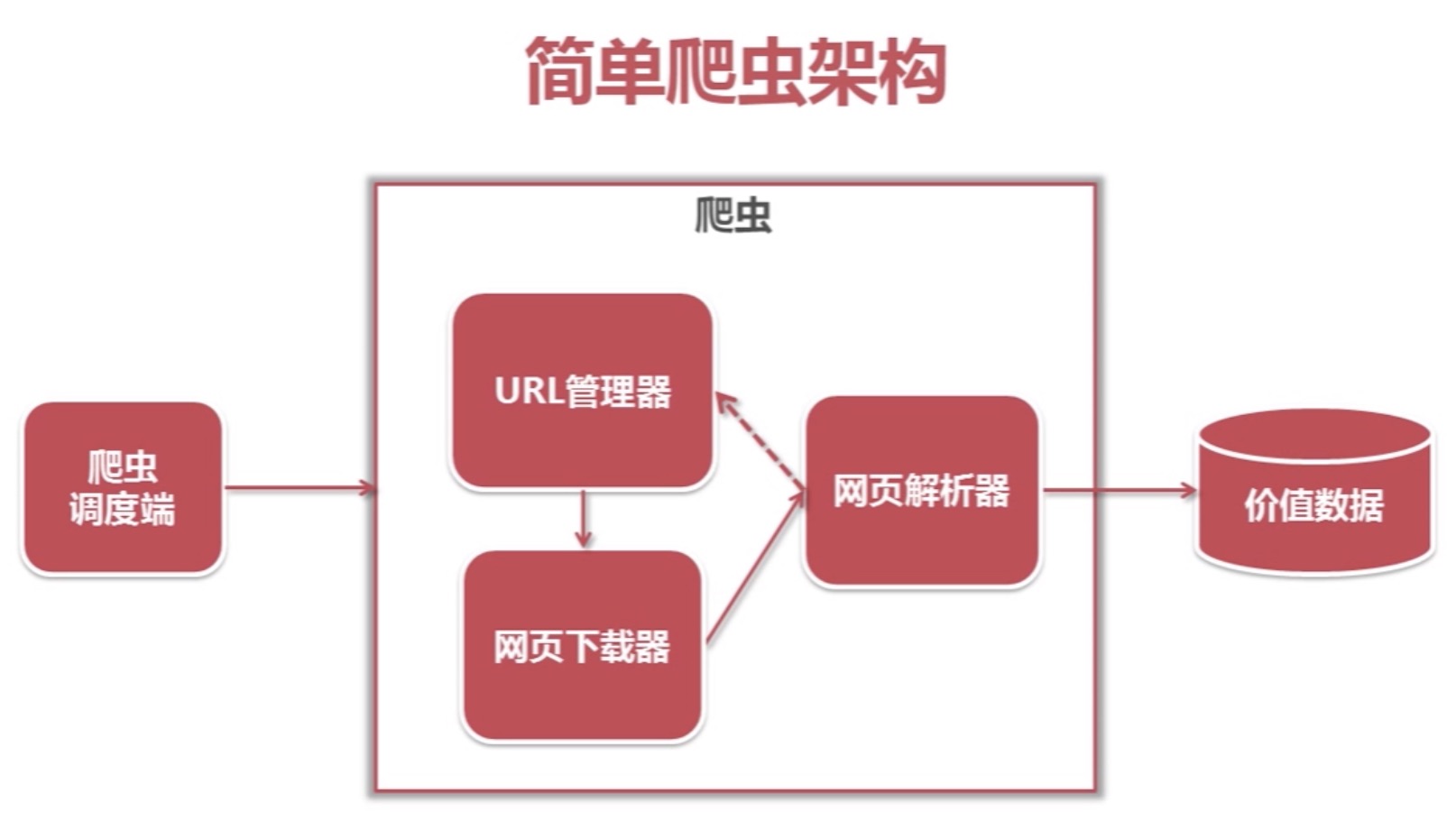
爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器” 网页解析…
xcode-select --install ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" brew se…
搜索引擎通过一种程序“蜘蛛”(又称spider),自动访问互联网上的网页并获取网页信 息。您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被蜘蛛访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎…